In my master’s thesis from 2014, I developed a chess player which learned to play chess scratch using what is now known as Deep Reinforcement learning. I was jointly supervised by
David Barber and
Peter Dayan, to whom I owe much gratitude for their persistent teaching and supervision. The thesis used (deep) convolutional neural networks trained with a combination of supervised and reinforcement learning. These very same components proved to be critical to the success of
AlphaGo in beating the world’s leading Go champion in 2016.
Here is the gist of the idea (in case you don’t have the time to read through the 160 pages thesis). Perhaps the easiest way to think of a chess board position is as a 3D tensor, where a piece on a particular board square is mapped to a binary variable:
I developed this representation and used it as an input to feed-forward neural networks and convolutional neural networks. For the convolutional networks, I fixed each convolutional filter in the first layer to take inputs from all piece type and convolved them over spatial regions (squares a-h, 1-8).
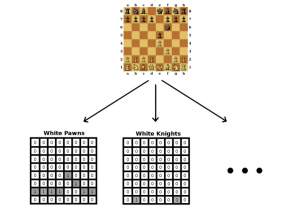
I used this setup to attack two different – but highly related – tasks. First, I trained models to predict the winning player during each move of a game. These models were trained using a database of games between highly skilled chess players. In this regard, the neural networks performed much better than linear models (such as logistic regression), and in fact reached a performance on par with a logistic regression based on hand-crafted expert features!
Next, I used the representation to actually learn to play chess using Deep Reinforcement Learning. I let the models play against themselves using a tree-structured Reinforcement Learning method called TreeStrap, a method developed by Joel Veness and colleagues in “Bootstrapping from Game Tree Search”. Not surprising, the results were very encouraging!

